
Neste post, dou início a um tema no qual mergulharei em vários momentos no blog: o Modelo CUB aplicado em People Analytics, uma interpretação da economia comportamental sobre os processos de decisão pelos quais as pessoas passam ao responder a questionários. Vou falar sobre como calcular e reduzir os ruídos nas pesquisas para chegar mais perto do resultado do sentimento real das pessoas a respeito das perguntas realizadas. Além disso, aprofundarei sobre como é possível determinar quais são os principais fatores que influenciam esse sentimento. Sempre com o eNPS como fio da meada, trazendo referências com dados reais para esse tipo de pesquisa.
No post de hoje falo sobre como a economia comportamental modela e como calcular a incerteza das pessoas ao responder a questionários, como o do eNPS.
Uma pequena revisão sobre como o eNPS é calculado
O eNPS1 é uma métrica muito utilizada pelas áreas de Recursos Humanos como um indicador para medir a experiência do funcionário (isso é discutível, e pretendo escrever sobre isso em outro post). A sua variação e magnitude movimentam a área para entender o que está acontecendo na empresa e nos departamentos, definindo prioridades, metas e cobranças. Muitas vezes, um dos principais trabalhos de People Analytics é responder a questionamentos como “por que o eNPS caiu?”, “o que fazer para subir o eNPS?” e “qual será o eNPS se fizermos X?”. Investe-se muito recurso da companhia em torno dessa métrica. Além disso, coisas interessantes acontecem na cabeça das pessoas ao responderem à pergunta que resulta no indicador, algo que impacta nos resultados finais e a economia comportamental ajuda a entender e explicar.
A medida do eNPS é simples. Pergunta-se aos colaboradores algo na linha de “Qual a probabilidade de você recomendar a [empresa X] a um amigo ou colega para se trabalhar?”. Ao respondente, é apresentada uma escala de zero a dez, com o menor valor representando o conceito de “muito improvável” e o maior valor, o conceito de “muito provável”. A pessoa deve escolher a categoria que acreditar ser a mais adequada de acordo com o seu sentimento. Depois de coletadas as respostas, elas são classificadas em três grupos:
- Detratores: todos aqueles que selecionarem notas entre 0 e 6 (inclusos);
- Neutros: todos aqueles que selecionarem notas 7 ou 8;
- Promotores: todos aqueles que selecionarem notas 9 ou 10.
O indicador final será igual ao percentual de promotores reduzido do percentual de detratores , e depois multiplicado por 100. Assim,
A métrica varia, portanto, entre -100 (quando todos são detratores) e 100 (quando todos são promotores). Após o cálculo do resultado, o valor agregado também é classificado em diferentes zonas, sendo a de excelência (eNPS 75 ou acima), a de qualidade (50 a 74), a de melhoria (0 a 49) e a crítica (-100 a -1). Já vi variações dessas zonas, e não há, portanto, um rigor metodológico muito forte nesse sentido. Mas a classificação já ajuda as áreas de Recursos Humanos a interpretar o resultado.
Comportamentos e vieses do funcionário ao responder ao eNPS e a outros questionários
É comum que sentimentos ou conceitos subjetivos não acessíveis diretamente sejam mensurados a partir de questões com escalas categóricas ordenadas. Por exemplo, a satisfação com o trabalho não pode ser observada diretamente, mas pode ser inferida por meio de questionários com validação científica2. Ao analisar como o respondente se posiciona nessas escalas, conseguimos mapear o nível de satisfação da pessoa com o trabalho. Esse tipo de variável oculta e abstrata é chamada de variável latente3, como é o caso do eNPS. Ao responder a esse tipo de questão, o colaborador passa pelo desafio de transformar um sentimento, de intensidade contínua, em uma escala de classificação que é discreta e ordenada. Ele precisará traduzir esse conceito interno, tendo que adaptá-lo e encaixá-lo em uma resposta categórica4.
Diferentes vieses podem adicionar ruídos a esse tipo de pergunta. Por exemplo, há o viés de desejabilidade social5, onde o respondente escolhe uma categoria que seja socialmente aceitável, ao invés de revelar sua verdadeira percepção sobre o tema. No caso do eNPS, a pessoa pode escolher respostas mais positivas para melhorar sua percepção social de pessoa bem-sucedida e inteligente, capaz de realizar boas escolhas de carreira, e com mais opções de trabalho no mercado, o que não seria compatível com um baixo nível de recomendação no eNPS.6
Também há um conflito interno entre o desejo de expressar os reais sentimentos sobre o tema e o esforço necessário para a elaboração da resposta. Isso faria com que o colaborador escolhesse uma categoria minimamente aceitável, traduzindo apenas parcialmente o sentimento ao mesmo tempo que minimiza o empenho para responder. Este comportamento, chamado de satisficing7, reduz a precisão da resposta. Além disso, outros vieses podem interferir na resposta, como um conhecimento limitado sobre o problema em questão, falta de experiência no tema, tempo de resposta, entendimento da pergunta e dúvidas sobre a escala, entre outros.
Calculando o peso dos vieses nas respostas através do modelo CUB
Em uma interpretação utilizada na economia comportamental, os diversos vieses, ruídos e dúvidas que interferem na escolha da categoria a ser respondida são chamados de incerteza (uncertainty). Ela afasta a resposta da realidade, acabando por adicionar erro à medida do indicador e, no caso do eNPS, pode impactar o resultado final. Já a verdadeira inclinação da pessoa em relação ao tópico da pergunta, influenciada pelos comportamentos, conhecimentos e experiências do respondente a respeito do tema da pergunta, é chamada de sentimento (feeling). A resposta final dada pela pessoa seria, então, uma combinação desses dois diferentes fatores, que atuam simultaneamente no momento de preenchimento do questionário.8
Para simular esse processo de escolha, uma classe de modelos estatísticos foi desenvolvida a partir do início dos anos 2000, chamada de Combinação de uma Distribuição Uniforme Discreta e uma Distribuição Binomial Deslocada (Combination of a Discrete Uniform and a Shifted Binomial Distributions), conhecida como CUB9. Esta classe permite estimar, a partir de uma amostra de respostas ao questionário, qual o peso da incerteza e do sentimento no momento das respostas, permitindo, assim, avaliar a qualidade das informações recebidas a partir da pergunta formulada, da escala escolhida e do contexto de aplicação.
Como o nome do modelo já diz, essa inferência é realizada a partir da combinação de duas distribuições de probabilidades diferentes. A primeira, a Discreta Uniforme, pressupõe que a escolha da categoria é aleatória e com igual probabilidade de escolha para cada categoria. Ou seja, não adiciona nenhuma informação a partir da resposta, pois, nesse caso, o respondente estaria chutando uma categoria aleatoriamente. Esta distribuição representa a incerteza. Ela pode ser representada matematicamente assim:
onde é a probabilidade sob incerteza, representa a variável que está sendo medida, e a resposta dada. Já representa o número de categorias da escala. Assim, pode-se ler essa expressão como “a probabilidade da resposta ser igual a uma determinada categoria é igual a 1 dividido pelo número de categorias”. Ou seja, cada resposta possível tem a mesma probabilidade que qualquer outra. Em um questionário com 11 categorias, por exemplo (caso do eNPS), a probabilidade associada a cada categoria é de ou aproximadamente 9%.
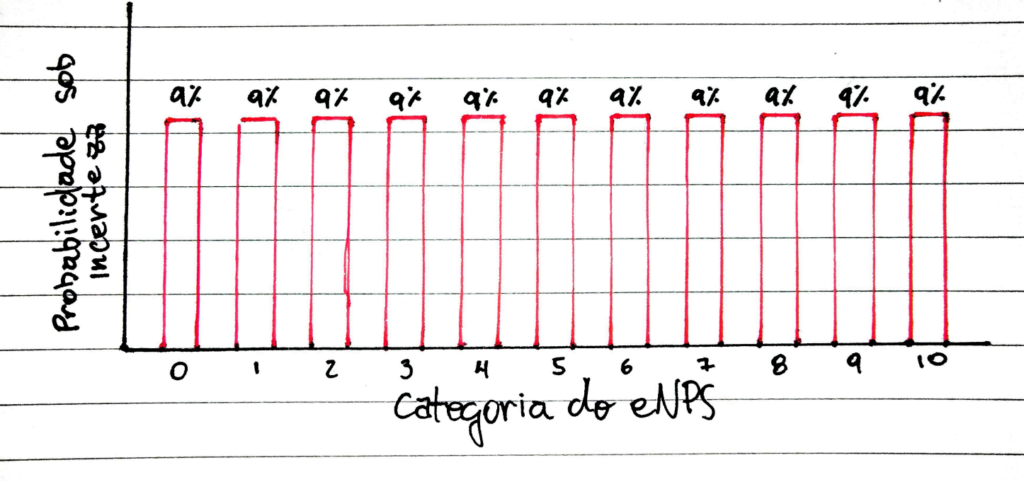
Figura 1 – Probabilidade de escolha de cada categoria sob incerteza
Já a Distribuição Binomial Deslocada é utilizada para representar as probabilidades de resposta em torno de uma tendência central ou sentimento médio em questões categóricas ordenadas. A partir dela é possível descobrir qual a proporção esperada de respostas em cada categoria10. Os detalhes dessa função serão explorados no terceiro post. Por enquanto, vamos chamá-la de , que é uma função do sentimento .
onde é a probabilidade de escolha da categoria a partir do sentimento . Podemos ler essa formulação matemática como “a probabilidade de um sentimento assumir o valor de resposta é dada pela função aplicada ao valor da resposta e ao sentimento “.
O modelo CUB mistura as duas formulações em uma só, utilizando o parâmetro para estimar o peso de cada formulação:
Assim, quanto maior for o termo , maior peso é dado para a distribuição uniforme discreta, o que significa que a incerteza ao responder é maior, revelando uma carga de vieses maior durante o processo de resposta.
Teste real com eNPS
Em meu trabalho final na especialização em Data Science e Analytics11, pude realizar um teste empírico dessa formulação com dados reais de respostas de eNPS. Nele, o componente de incerteza teve significância estatística, com peso de 7%. Atribuir essa intensidade à incerteza faz com que o modelo explique melhor os dados reais e indica um viés que pode impactar os resultados finais do indicador.
Uma outra maneira de interpretar o resultado é que 7% das respostas foram dadas ao acaso. Isso pode parecer pouco, dependendo do contexto. No entanto, a forma como o eNPS é obtido e calculado faz com que exista um desbalanceamento da incerteza, pois existem muito mais categorias detratoras do que neutras ou promotoras. Considerando que, no momento da resposta, o funcionário deve escolher entre 11 diferentes níveis de recomendação, e que 7 dessas categorias são detratoras, temos que 64% da incerteza conta como uma redução do indicador de eNPS final, enquanto apenas 18% aumenta o indicador. Isso já faz com que exista um eNPS de -45 para 7% da população em decorrência, apenas, das dúvidas geradas no processo de resposta.
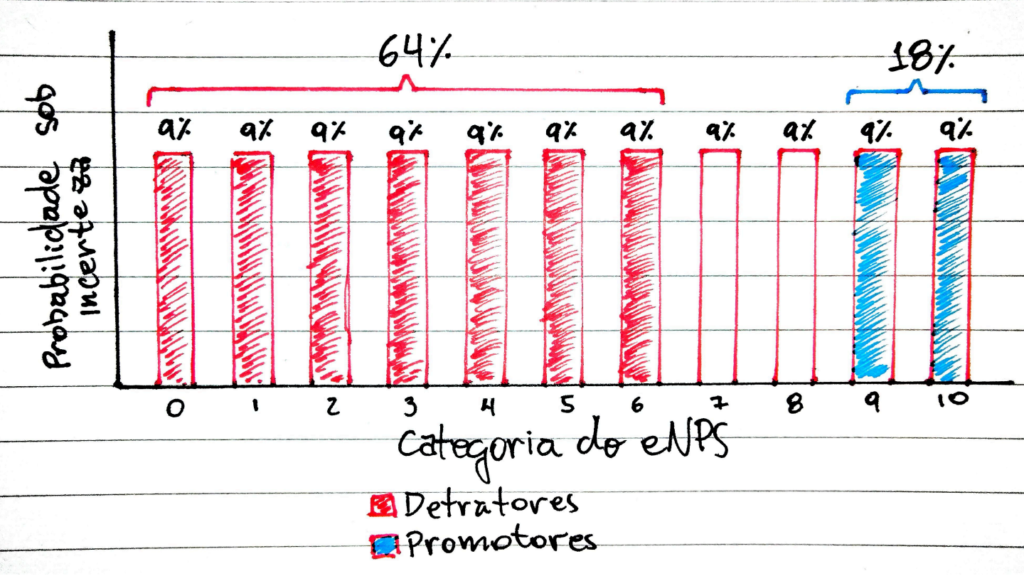
Figura 2 – Desbalanceamento do impacto da incerteza no eNPS
Dissimilaridade
Contudo, para entender se o modelo está em conformidade com os dados reais, é preciso aprofundar a análise. Para isso, podemos utilizar o índice de dissimilaridade. Ele mede a conformidade dos dados reais ao modelo estimado, permitindo, assim, entender se o modelo está explicando de maneira satisfatória o que está acontecendo na amostra. A medida pode ser definida como12
onde o termo é o valor esperado para a resposta, representa o valor observado da resposta dada, o número de respondentes e o subscrito representa o indivíduo. De maneira simplificada, o indicador representa o percentual de respostas que precisariam ser modificadas para que o modelo tenha 100% de acerto. Assim, a métrica varia entre 0% — nenhuma resposta precisaria ser modificada — e 100% — todas as respostas teriam de ser modificadas.
No caso do eNPS, a dissimilaridade foi de 11,6%. Uma regra de bolso é que dissimilaridades com valores entre 10-15% já merecem atenção13, podendo indicar uma não adesão do modelo aos dados observados.
A partir dessa análise, podemos concluir que a inclusão da estimativa de incerteza não está sendo suficiente para explicar os dados encontrados no eNPS. Isso pode acontecer em outras pesquisas também. Por isso, é muito importante verificar se o modelo está conseguindo prever corretamente a distribuição de respostas. Outro fenômeno pode estar influenciando as respostas, e vamos, juntos, entender o que é, como descobrir e o que fazer no próximo post da série.
- eNPS é uma sigla para “employee net promoter score“, uma derivação do NPS que foi originalmente proposto por REICHHELD, Frederick F. 2003. The one number you need to grow. Harvard business review, v. 81, n. 12, p. 46-55. ↩︎
- Por exemplo, ver SIQUEIRA, Mirlene Maria Matias. 2002. Medidas do comportamento organizacional. Estudos de Psicologia (Natal), v. 7, p. 11-18. ↩︎
- Diferentemente do que muitas pessoas pensam, latente não é aquilo que está evidente ou patente, mas justamente o oposto, é aquilo que está escondido, oculto e invisível. ↩︎
- CORDUAS, Marcella; IANNARIO, Maria; PICCOLO, Domenico. 2009. A class of statistical models for evaluating services and performances. In: Statistical methods for the evaluation of educational services and quality of products. Physica, Heidelberg p. 99-117. ↩︎
- ARNOLD, Hugh J.; FELDMAN, Daniel C.; PURBHOO, Mary. 1985. The role of social-desirability response bias in turnover research. Academy of Management Journal, v. 28, n. 4, p. 955-966. ↩︎
- Este tipo de viés está mais presente em questionários aplicados em forma de entrevista. ↩︎
- KROSNICK, Jon A. 1991. Response strategies for coping with the cognitive demands of attitude measures in surveys. Applied cognitive psychology, v. 5, n. 3, p. 213-236. ↩︎
- GAMBACORTA, Romina; IANNARIO, Maria. 2013. Measuring job satisfaction with CUB models. Labour, v. 27, n. 2, p. 198-224. ↩︎
- PICCOLO, Domenico. 2003. On the moments of a mixture of uniform and shifted binomial random variables. Quaderni di Statistica, v. 5, n. 1, p. 85-104. ↩︎
- A escolha por essa função de distribuição de probabilidade para simular escolhas ordenadas é reflexo de uma hipótese sobre o funcionamento do processo decisório. Por exemplo, considera-se que as distâncias entre as categorias são as mesmas. Como esse processo não é observável, existem outras interpretações. Uma discussão pode ser vista em PICCOLO, Domenico; SIMONE, Rosaria; IANNARIO, Maria. Cumulative and CUB models for rating data: a comparative analysis. International Statistical Review, v. 87, n. 2, p. 207-236, 2019. ↩︎
- MITTMANN, Zenir. eNPS: uma estimativa dos componentes “feeling” e incerteza através do modelo CUB. Orientador: Auberth Henrik Venson. 2023. Monografia (MBA em Data Science e Analytics) – USP – Esalq. Download aqui ↩︎
- Simonoff, Jeffrey S. 2003. Analyzing categorical data. New York: Springer. ↩︎
- ARNOLD, op. cit. ↩︎
Deixe um comentário