Este é o segundo e último post sobre como usar estatística bayesiana para montar um preditivo de turnover no Excel (ou onde mais você achar interessante). Nele, vou explorar a importância da independência entre as variáveis, como calcular o peso de cada uma delas a partir do poder preditivo e, finalmente, a implementação em planilha. O primeiro post é a base para entender toda a lógica do princípio de Bayes, que permite você atualizar seu conhecimento sobre qualquer coisa (inclusive sobre probabilidades de pedido de demissão), então se você ainda não o conhece, sugiro que dê uma passada nele.
Independência das variáveis
No último post finalizamos com a apresentação do algoritmo bayesiano que permite a inclusão de diversas variáveis diferentes para calcular a probabilidade de saída de alguém. Um ponto relevante para o uso desse algoritmo no dia a dia é que as variáveis utilizadas precisam ser independentes, ou seja, devem realmente representar uma informação nova. Um professor antigo meu diria que essa é uma suposição “heroica”, mas no contexto da análise bayesiana isso é chamado de naïve (ingênuo).
É fácil de entender por que isso é necessário. Imagine, por exemplo, que você use duas métricas no preditivo: uma que representa o tempo sem aumento e outra que represente a insatisfação com a remuneração. Parece evidente que essas duas variáveis deveriam possuir alguma correlação, pois seria esperado que pessoas com mais tempo sem receber aumento salarial estivessem mais insatisfeitas com a sua remuneração. E se usarmos ambas em conjunto no princípio bayesiano, parte do crescimento na probabilidade estaria duplicado, inflando artificialmente o risco de saída.
Como estamos pensando em uma formulação simples, no Excel, minha sugestão é: sempre que uma pessoa possuir duas características em variáveis correlacionadas (seja estatística ou teoricamente), utilize apenas uma delas, escolhendo aquela que possua o maior poder de movimentar a probabilidade.
Calculando o poder preditivo de uma variável
Para entender qual variável é aquela que mais movimenta o preditivo, uso uma métrica que chamei de “poder preditivo”, ou . Eu realmente não sei se essa métrica já existe ou se tem outro nome. Mas, quando me deparei com essa necessidade, pensei que nada seria melhor para calcular o poder preditivo em um modelo bayesiano do que usar o próprio princípio de Bayes.
Para calcular, você deve considerar que o prior bayesiano é de 50%. Assim, qualquer nova variável, após a atualização da probabilidade, vai se distanciar no máximo 50 pontos percentuais da probabilidade inicial1 (vai atualizar, no máximo, para algo próximo de zero ou de cem). Dividindo essa distância por 50%, temos o quanto que ela se afastou percentualmente do prior. Por fim, multiplica-se por 100 e extrai-se o módulo, para ter apenas números positivos. Assim, temos uma métrica que varia entre 0 e 100, onde, quanto maior for o valor, maior o impacto daquela variável. Matematicamente podemos calcular o poder preditivo da seguinte forma
_
_
onde:
- é a probabilidade do evento dada a evidência, calculada a partir do prior bayesiano de 50%. No nosso exemplo inicial, é a probabilidade de turnover (evento) dada a insatisfação com a remuneração (evidência), considerando o prior de 50%.
- é a probabilidade de encontrar a evidência no grupo em que o evento ocorreu. No nosso exemplo inicial, é a probabilidade de estar insatisfeito com remuneração (evidência) dado o turnover voluntário (evento).
- é a probabilidade de encontrar a evidência no grupo em que o evento não ocorreu. No nosso exemplo inicial, é a probabilidade de estar insatisfeito com a remuneração (evidência) dado que não houve pedido de demissão (não evento).
- é o poder preditivo da variável, que varia entre zero e cem.
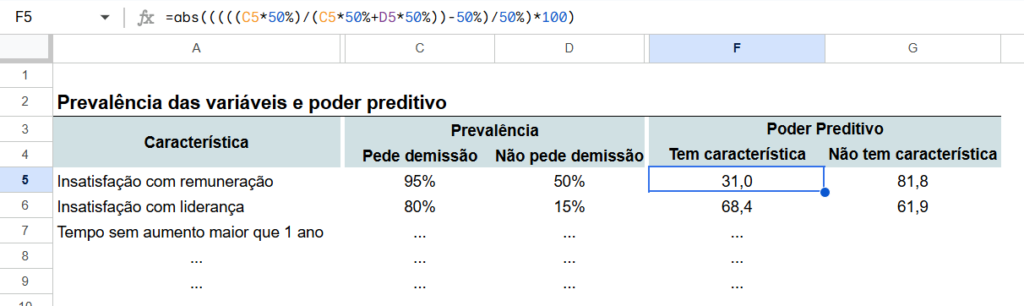
Vamos aplicar o cálculo às variáveis de exemplo que usamos. Primeiro, considerando a insatisfação com a remuneração.
_
Como em nosso exemplo do primeiro artigo a — que representa o percentual de insatisfeitas com remuneração dentro do grupo que pede demissão— é igual a 95%, e a — que é a probabilidade de estar instatisfeito com remuneração dentro do grupo que não pede demissão — é 50%, podemos substituir e calcular o poder preditvo como
_
_
Assim, ao aplicar a fórmula do poder preditivo, vemos que a insatisfação com a remuneração tem poder preditivo de 31,0. Agora, considerando a informação de insatisfação com a liderança, onde a probabilidade de insatisfação com liderança dentro do grupo que pede demissão é de , enquanto no grupo que não pede é , podemos calcular o poder preditivo da seguinte forma:
_
_
_
Nesse exemplo, vemos que a insatisfação com a liderança possui um poder preditivo substancialmente maior, de 68,4. Sabemos, assim, que estar insatisfeito com a liderança deve ter um impacto maior na nossa crença sobre a saída voluntária do talento. Caso houvesse uma correlação entre as duas variáveis analisadas, a escolha seria excluir a variável “insatisfação com a remuneração”. Contudo, nesse caso específico, é provável que não exista correlação, ou que ela seja baixa, o que permitiria manter as duas variáveis.
Preditivo no excel
Primeiro, certamente existem maneiras melhores de fazer esse preditivo do que no Excel. Existem bibliotecas prontas em Python e em R para rodar esse tipo de análise. Mas fazer no Excel tem um didatismo importante, pois tem a força de fixar todo o conceito apresentado a partir da programação do princípio bayesiano em fórmulas, o que é melhor que usar bibliotecas prontas (ainda que você também possa implementar em Python ou em R sem o uso delas).
Outra vantagem é que é mais democrático, reduz uma barreira inicial de conhecimento, acelerando a entrega de valor da área. E, como o princípio é simples — diferentemente de outros modelos preditivos que necessitam de cálculo numérico (como regressões logísticas) —, é viável sua implementação em planilhas. A primeira implementação fiz no Google Sheets, como prova de conceito e forma de fixação do princípio bayesiano. E, no fim, considerando que a base de dados não era gigante (mas grande o suficiente), continuou rodando em planilha por bastante tempo.
Por fim, utilizar esse método e rodar em planilhas traz uma vantagem de explicabilidade. Em modelos de Machine Learning (usando regressão logística e redes neurais, por exemplo) pode ser difícil explicar por que um funcionário possui risco elevado de saída. Nesse modelo, é fácil verificar os motivos e auditar as contas, o que gera confiança. Além disso, você consegue simular facilmente o quanto uma mudança em uma das variáveis impacta na probabilidade de saída de uma pessoa em específico, ajudando na tomada de decisão.
Passo 1 – Definição das variáveis
Defina as características ou evidências que serão utilizadas e informe a prevalência delas no grupo de quem pede demissão e no grupo de quem não pede demissão. Coloque essas informações em uma aba da planilha. Calcule também, em outra coluna, o poder preditivo de cada variável, incluindo o poder preditivo de não possuir a característica em questão (por exemplo, não estar insatisfeito com a remuneração). Se for muito baixo, considere não usar a informação.
_
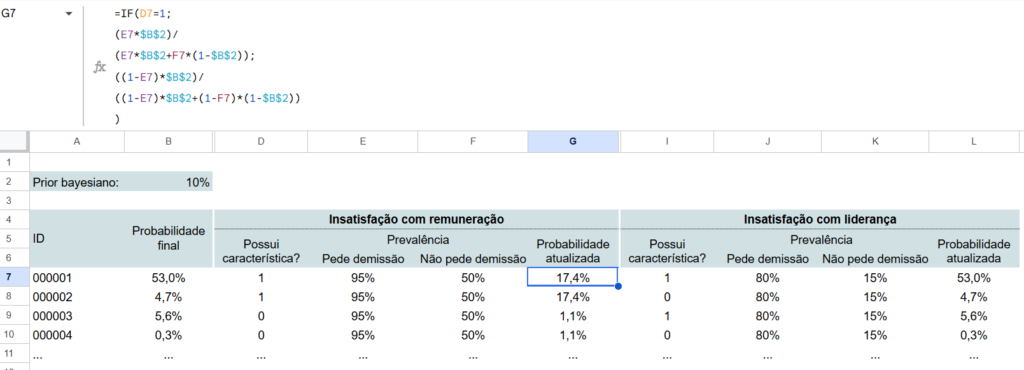
Passo 2 – Cálculo das probabilidades
Em outra aba, considere uma linha para cada previsão de turnover que você deseja fazer. Cada variável pode ter 4 colunas, sendo a primeira contendo o valor 1, se a pessoa tiver a característica, e 0, se não tiver. Na segunda, traga a prevalência da característica no grupo de quem pede demissão. Na terceira, a prevalência da característica no grupo que não pede demissão. Na quarta, aplique o princípio bayesiano, considerando o prior igual ao seu valor histórico de turnover voluntário.
Nas próximas colunas, repita o processo, mas considerando como prior bayesiano aquele calculado na variável anterior. Faça isso até finalizar todas as variáveis.
_
E está pronto!
Minha sugestão é, depois disso, acompanhar e verificar se as pessoas com maior probabilidade de saída são aquelas que estão saindo mais, e se as que têm menor probabilidade estão saindo menos. Assim, você pode ajustar variáveis, identificar problemas e ainda aumentar a aderência às ações derivadas do preditivo.
Ideias de usos para o preditivo de turnover
Como disse na introdução, se não há clareza sobre como utilizar o preditivo e qual problema se quer resolver com ele, há grande possibilidade de não valerá a pena (a não ser para aprender alguma coisa nova, o que sempre vale). Muitas vezes, na companhia, é muito mais importante saber por que as pessoas estão saindo, de uma forma confiável, do que saber quem tem mais chances de sair. No primeiro caso, você atua no atacado, e no segundo, no varejo. Mesmo assim, algumas coisas podem ser feitas com um preditivo desse tipo.
1 – Identificação das variáveis que impactam o turnover
Por causa do poder preditivo, é possível comparar o impacto de cada uma das variáveis, e, assim, saber quais têm maior peso nas saídas. Ainda assim, uma variável com poder preditivo muito alto pode não ser relevante se tiver uma baixa prevalência. Por exemplo, você poderia descobrir que pessoas com salário acima de R$ 200 mil têm baixa probabilidade de sair, mas a quantidade de pessoas é baixa e, portanto, isso não resolveria o problema de turnover da companhia (a não ser que seja viável pagar um salário de R$ 200 mil para todo mundo).
2 – Identificação tendência futura do turnover geral
Caso aplique o preditivo para toda a companhia, considerando que você utilizou variáveis que aumentam, mas também que reduzem a probabilidade de saída, de maneira equilibrada, se a média das probabilidades for menor que o prior bayesiano, isso pode significar tendência de queda; se for maior, tendência de alta. Ainda assim, existem fatores externos que podem influenciar mais que essas variáveis (por exemplo, turnover em companhias que disputam o mesmo mercado de trabalho). Então, uma leitura correta dessa informação seria considerá-la como uma tendência futura com base nas variáveis internas conhecidas.
3 – Retenção de talentos chave
A aplicação mais interessante que fizemos foi a seguinte. A partir do preditivo, criamos um ranking, onde era possível classificar as pessoas com maior risco de saída. Consultores de RH recebiam a informação de talentos com maior risco, e apenas essa informação. Eles marcavam, conforme possível, conversas com essas pessoas, onde falavam sobre os assuntos que julgavam importantes. Como não existia condição de conversar com todos, apenas uma parte dos talentos em risco teve essa conversa. Ao acompanhar o desfecho em turnover voluntário de talentos em alto risco, aqueles que conversaram com os consultores tinham uma retenção de quase 100%, enquanto os demais estavam com turnover próximo à média de probabilidade calculada inicialmente. Uma simples conversa, explorando os assuntos de acordo com a sensibilidade dos consultores de RH, é capaz de reduzir drasticamente a probabilidade de saída de um talento. E o preditivo ajuda a indicar quem deve ser priorizado nessa conversa.
Indicações para aprofundamento no tema
- Vídeo The Bayesian Trap, do canal de youtube Veritassium.
- Vídeo Bayes theorem, the geometry of changing beliefs, do canal 3Blue1Brown.
- Aula do Altay de Souza de Estatística Psicobio I – Introdução a Inferência bayesiana, do canal Cientística.
- Slides de aula do Ben Lambert, sobre estatística bayesiana.
- Livro a A Student’s Guide to Bayesian Statistics, do Ben Lambert.
- Livro de Sharon Bertsch McGrayne, que conta sobre a história do teorema, da sua dupla descoberta, esquecimento e conflito com a estatística frequentista: The Theory That Would Not Die: How Bayes’ Rule Cracked the Enigma Code, Hunted Down Russian Submarines, and Emerged Triumphant from Two Centuries of Controversy.
- Como estamos falando de probabilidade, esse é o limite teórico, mas de fato a distância nunca vai chegar a 50%. ↩︎
Deixe um comentário